By screening 407 compounds directly in cells scientists in Austria and the US have found that they bound with 2305 proteins not previously known to have any such interactions. Georg Winter at the Centre for Molecular Medicine (CEMM) of the Austrian Academy of Sciences in Vienna and colleagues used the large compound collection to create an openly accessible dataset. With that data, they then taught a machine learning system to accurately predict how promiscuously the compounds bind with proteins, and showed it could readily predict other properties.
It’s especially important that the large dataset of protein–ligand interactions and AI tool is now available for other researchers to use, Winter says. He also sees the large number of new proteins that disease researchers can target as significant. ‘This is very exciting since it implies that the undrugged, yet druggable proportion of the human proteome might be much larger than we anticipated,’ he tells Chemistry World.
No compounds are known to bind around 80% of the entire set of proteins a human can make, which is collectively known as the proteome. At the same time drug researchers usually identify proteins to target to treat diseases in a relatively slow way. Scientists have previously sought to change that by screening compounds directly inside cells. That approach connects each compound being screened to a highly reactive diazirine, which permanently attaches through a covalent bond to any protein nearby when exposed to ultraviolet light.
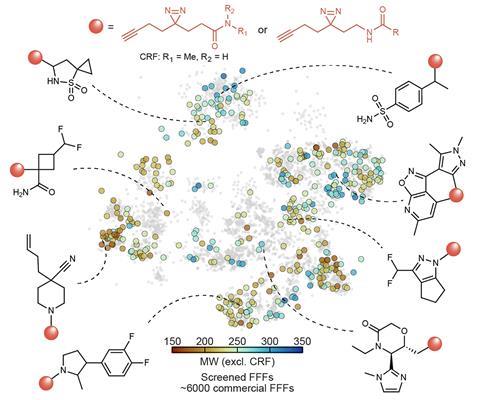
Where previous studies were limited to testing about 20 compounds, Winter’s team was able to screen 407, portioned out seven compounds per tube together with immortalised human kidney cells. After breaking the cells open, Winter’s team, including collaborators at drug giant Pfizer, could identify which compounds had bound to which proteins using highly sensitive mass spectrometry techniques.
The team found 47,658 compound–protein interactions involving more than 2600 proteins, most of which had never had any interactions documented before. The researchers then modified the structures of compounds involved in three such interactions to produce probes that may be used to affect protein function in future.
Winter and colleagues also used the large dataset of reactions to train a pre-existing machine learning tool to distinguish ‘promiscuous’ compounds that bound to many proteins from ‘nonpromiscuous’ ones only binding to a few. They could also build bespoke machine learning models to predict other properties, such as the probability of compounds to bind to a particular class of protein. The team now wants to produce even bigger datasets, and to target non-protein targets such as nucleic acids.
Cheryl Arrowsmith, chief scientist of the Structural Genomics Consortium (SGC) at the University of Toronto, Canada, calls the results ‘an impressive body or work’. The paper is ‘an important step toward mapping drug-like chemistry space onto the human proteome’, she adds. ‘It is the type of study needed for studying and understanding the “dark proteome”,’ Arrowsmith says. ‘The open data resource itself is notable, and especially important for the community to use and explore its usefulness, including generating their own machine learning models.’